
Multi-Cloud & On Premise : nos experts Cloud au Devoxx France !
Lire la transcription
Bonjour et bienvenue à tous et à toutes. Nous sommes réunis aujourd'hui pour la session multicloud et une prémisse : dépassons les frontières, tirons le meilleur de chacun des mondes.
Alors je vais me présenter. Je m'appelle Sébastien Thomas, je suis cloud architecte Azure après avoir un long passé de développeur et de software architecte.
Je suis Francis Besson, je suis cloud solution architecte AWS après un passé tant en infra et en dev dans un petit peu tous les domaines de l'IT.
Et donc nous travaillons tous les deux pour la société Open. Open est une ESN qui compte 4000 collaborateurs répartis dans 16 implantations dont 14 en France. Open accompagne ses clients dans leur transformation digitale et IT. Open compte plus de 500 experts et architectes dans les domaines Cloud et DevOps, data IA et modern digital workspace.
Suite à des discussions entre différents architectes chez Open, nous avons découvert que nous avions tous une expérience ou plusieurs expériences sur différents clouds, potentiellement aussi sur plusieurs clouds à la fois chez certains de nos clients. Et suite à ces discussions, nous avons vu que nous pouvions avoir une démarche un petit peu différente de celle qui est classiquement admise, qui est souvent une opposition entre Kubernetes et les solutions PaaS cloud native, donc les services, les plateformes as a service.
Et donc cette opposition, souvent les clients choisissent l'un ou l'autre, l'une ou l'autre des implantations. Et nous, notre approche c'est plus de choisir ce qui correspond le plus au contexte du projet et peut-être aussi de choisir l'une et l'autre des implantations selon le cloud ou le fournisseur.
Donc dans la démarche que nous allons vous présenter aujourd'hui, nous allons donner le choix au projet, faire en sorte que ce soit vraiment le contexte du projet, le besoin de chacun des différentes solutions nécessaires qui fasse que le choix va se porter et permettre de faire en sorte que le code métier puisse être déployé sur n'importe quel cloud. On va faire en sorte aussi dans cette démarche de permettre d'adapter potentiellement des applications legacy qui en appliquant la démarche puissent faire du move to cloud. On va aussi permettre une meilleure répartition des compétences, aussi à garantir une meilleure gouvernance avec cette démarche.
Bienvenue dans le multicloud. Alors pour le reste de la présentation nous allons considérer que le on-premise, des data centers, sont un cloud comme un autre. Donc on pourra parler aussi bien de AWS, Azure, on va pouvoir citer les cloud providers mais on pourrait aussi bien citer OVH, Scaleway, Ionis et bien d'autres, mais aussi le déploiement on-premise donc dans des data centers ou dans des Kubernetes.
Alors il y a beaucoup de raisons de multiplier les clouds. Ça peut être parce qu'une équipe data va avoir un besoin spécifique, ça peut être parce qu'on fait une fusion acquisition d'une société, qu'on se retrouve avec deux tenants différents, des applications qui vont être réparties chez différents cloud providers. On peut avoir les besoins de respecter des conditions contractuelles ou des conditions réglementaires comme le RGPD et faire en sorte qu'on puisse déployer les données le plus proche possible des clients. Ça peut être parce que le type de ressource que l'on souhaite doit être disponible le plus proche possible de nos clients. Ça peut être pour des besoins d'utilisation de clouds souverains ou ça peut être parce que pour des raisons spécifiques on ne veut pas être dépendant d'un cloud provider.
Quel que soit le cloud provider, on va avoir des contraintes. On va avoir des besoins de compétences spécifiques parce que chaque cloud provider, même s'il implémente des types de ressources qui sont similaires, on va avoir des petites différences dans l'implémentation, dans la gestion de la sécurité, la gestion des déploiements. Et donc toutes ces petites différences font qu'on va avoir des besoins d'expertise spécifiques. On va avoir aussi des besoins de compétences pour pouvoir faire du cloud public parce que cloud public veut dire que si on fait une mauvaise manipulation, on va se retrouver à exposer des données ou exposer des ports qui permettront peut-être à des pirates de pouvoir exfiltrer ces données.
On va avoir aussi, si on a du multicloud, on va avoir besoin d'avoir une vision des bonnes pratiques et une gouvernance qui sera nécessairement pour tous les clouds réunis. Donc il va falloir contrôler que les applications qui sont déployées selon le cloud respectent les bonnes pratiques. On va pouvoir, on va devoir mettre en place un certain nombre de contrôles pour respecter sur chacun des clouds que ces bonnes pratiques sont bien respectées.
Et enfin, on va avoir des besoins pour chercher des compétences. Si on cherche déjà une personne qui connaisse fonctionnellement notre métier, qui connaisse la technologie, c'est déjà compliqué à trouver ces personnes-là. Si en plus on leur demande de faire du cloud, on cherche des moutons à 5 pattes. Si on leur demande de faire tout ça et en plus connaître chacun des clouds sur lesquels on va s'implanter, on va pouvoir déployer, en fait on ne cherche plus des moutons à 5 pattes, on cherche des licornes.
Et donc le choix Kubernetes ou full native pour nous, c'est pas vraiment en fait un choix qu'il faut faire de façon brutale parce que chacun va avoir des avantages et des inconvénients. Par exemple, en cloud natif on va avoir des services managés par le provider et qui vont avoir des niveaux de service garantis. On va avoir un support existant sur du service PaaS, des évolutions régulières et des patchs de sécurité et une excellente résilience par défaut, parce que les providers cloud mettent les moyens matériels pour garantir que la solution soit toujours up. Et on a un choix de service complet. Néanmoins, dans certains cas, la personnalisation peut être limitée. De plus, à fonctionnalité équivalente, les services PaaS selon les cloud providers vont être légèrement différents. Et surtout, il y a toujours, c'est le pendant en fait de ces mises à jour régulières imposées par le provider, et on a toujours un risque de régression lors de ces mises à jour qui sont imposées.
À côté de ça, Kubernetes, on va avoir d'immenses possibilités de personnalisation. On va avoir une scalabilité ultrafine, on va pouvoir héberger n'importe quel conteneur applicatif ou de services type Kafka, type base de données, type IA. Mais on va avoir et on va avoir une maîtrise totale de la mise à jour et surtout on va retrouver Kubernetes en local chez tous les cloud providers ou même en on-premise sur un data center.
Néanmoins, les inconvénients de Kubernetes, c'est que c'est malgré tout du IaaS dans du IaaS, c'est-à-dire que la configuration, la résilience et la sécurité sont à la charge des équipes. C'est-à-dire qu'au lieu d'utiliser par exemple une base de données hébergée dans le cloud, si je décide de mettre mon MySQL ou mon Postgres dans mon Kubernetes, toute cette charge d'administration, tout ce qui est le patching, tout ce qui est la résilience et tout ça, c'est embarqué par l'équipe de développement. Ce n'est plus géré par le cloud. Donc c'est quand même quelque chose qui n'est pas anodin.
Et de plus, le fait de mettre un maximum de services dans un Kubernetes en se disant "j'héberge mon appli, mes bases de données, mon queuing, je vais effectivement pouvoir le porter d'un cloud provider à un autre", mais ça fait en sorte que mon cluster devient un SPOF (Single Point of Failure). Et donc c'est quand même une considération qu'il faut avoir. Et surtout c'est un écosystème donc on risque d'avoir des dépendances sur des produits et des éditeurs associés.
Et je pourrais continuer. Si on fait du multicloud en ayant fait le choix de Kubernetes, il faut savoir que quel que soit le provider sur lequel on va avoir, on va devoir respecter le rythme de déploiement de Kubernetes qui est une livraison d'une release majeure tous les 3 mois. Avec par exemple la version 1.26 où le démarrage de cette version c'est en avril 2023 en version stable et elle se termine à peu près une année après, donc on a un rythme d'une release tous les 3 mois avec jusqu'à 14 mois de support maximum et des risques de breaking change à chaque release.
Ce rythme imposé à nos équipes, ça peut être le rythme qui est imposé à nos équipes de développement, à nos équipes d'administration. Ce rythme imposé fait qu'il va falloir suivre le rythme et donc appliquer ces mises à jour avec les risques de régression que ça implique, ou alors devoir multiplier les clusters Kubernetes.
Et donc ce rythme-là, si on prend l'implémentation des cloud providers, en fait le support assuré par les cloud providers, on a un support des trois dernières releases uniquement, les trois dernières releases stables. Si on prend ce que ça implique de n'avoir que les trois dernières releases stables, si on est donc en dehors de ces trois dernières, on n'a plus de support, on ne bénéficie plus de niveau de service garanti. Donc on n'est pas certain que la machine puisse démarrer et exécuter notre charge de compute. Et on ne pourra pas faire non plus de mise à jour vers une version supérieure si on est en dehors du support. Et on ne pourra pas non plus créer d'instances. Donc si notre cluster vient à faillir, on ne pourra pas créer une version dans une version qui n'est pas qui ne fait pas partie des versions stables et on ne pourra pas le recréer dans le temps.
Donc le choix entre Kubernetes et le full cloud native pour nous, en fait c'est un choix qui a de toute façon des avantages et des inconvénients et il faut permettre au projet de choisir le meilleur compromis pour eux à un instant donné par rapport au budget, par rapport aux compétences qui sont disponibles à un certain moment. Et peut-être qu'il y a une équipe d'administration qui est prête donc on peut utiliser Kubernetes. Si on n'a pas d'équipe d'administration parce qu'on veut se déployer sur un cloud en avance de phase pour pouvoir le tester le temps de mettre en place une équipe d'administration pour ce cloud provider en particulier, ce choix n'est pas possible donc il faut leur permettre de quand même pouvoir déployer sur ce cloud.
Et ce choix, il n'est pas unique parce que les services des cloud providers changent régulièrement. On peut avoir un service qui sera beaucoup plus utile, beaucoup moins coûteux à gérer ou qui permet de faire des choses plus intéressantes. Et donc ce choix-là, il faut le laisser au projet dans le temps parce que dans 6 mois, dans un an, il faut pouvoir rechallenger ce choix et il faut permettre du coup au projet de pouvoir déployer là où il le souhaite. Peut-être pour se déployer sur AWS pour un projet data dans le Kubernetes en local et se déployer en même temps sur Azure ou sur GCP, il faut leur donner les moyens de déployer leur code métier.
Donc nous allons vous présenter une démarche qui permet de coller à tous ces besoins-là et Francis va vous présenter donc le fruit de ces tests.
Donc l'exemple que je vais vous présenter, en fait on va impliquer peu de services volontairement sur les différents clouds. L'objectif c'est pas de voir la richesse fonctionnelle de l'application qu'on présente mais c'est de plutôt d'avoir en tête la démarche qu'on a voulu mettre en œuvre et c'est une démarche que nous, on verrait bien généraliser.
Donc nous sommes dans le cas par exemple d'un développement sur une architecture hexagonale. Donc quand on a un développement en architecture hexagonale, on va avoir une première partie qui est le code métier qui est isolé en fait de toute la partie interaction avec l'écosystème dans lequel se trouve l'appli. Ce code métier, c'est celui qui contient la business value, qui va être complexe fonctionnellement parce que c'est lui qui implémente les règles métier de l'entreprise et il va avoir une évolution fonctionnelle fréquente. C'est l'agilité, on a des sprints, on implémente des features, c'est la vraie vie.
On va avoir une partie infra as code, c'est la partie qui va implémenter les services qui vont héberger l'application. Donc j'ai pris un exemple simple : S3 et storage container qui sont deux services similaires. Et entre nos deux couches en archi hexagonale, on va voir ce qu'on appelle un adaptateur. C'est porté par le nom, c'est ce qui va adapter l'application à son contexte infrastructure.
Si on regarde un petit peu plus loin, on voit que cet adaptateur en fait c'est quelque chose de simple fonctionnellement mais c'est très technique au niveau IT, parce que dans cet adaptateur on va retrouver une partie du code que j'ai appelé, que nous avons appelé SDK cloud. C'est ce code-là en fait qui va implémenter toute la couche technique d'interaction avec les services déployés. C'est ce code-là qui va implémenter la bibliothèque de l'hyperscaler. Par exemple, je dois, mon appli doit utiliser du S3, elle est en Python, bah ça va être Boto3. On va, c'est là où on va implémenter Boto3 pour les interactions.
Néanmoins, ce qu'on remarque, c'est que c'est ce code-là avec l'infrastructure, ce code qui implémente la sécurité. C'est-à-dire que si mon application doit interagir avec une base de données, c'est ce code-là qui va être responsable, selon l'archi qui a été déployée par exemple, d'aller lire un secret, de récupérer les login, de se connecter à la base ou d'y aller de manière transparente parce que l'infra as code a mis en place les rôles. Et surtout c'est un code qui est en fait intimement lié avec la couche IAC. En fonction de la façon dont j'ai sécurisé par exemple mon bucket S3 ou ma base de données, je ne vais pas me connecter forcément de la même façon.
Et je rajouterais que dans cette configuration-là, si on containerise l'application et qu'on la déploie sur un autre provider, on reste dépendant du S3 du storage. Donc on reste dépendant du cloud provider qu'on a utilisé dans notre partie adaptateur. Donc il y a quand même un travail à faire pour rendre notre application agnostique.
D'un autre point de vue, si je prends cette architecture hexagonale, on va voir qu'on va avoir des dev métiers qui vont faire l'application, le côté vraiment applicatif, et des dev IT qui vont faire le côté infra as code. Ici je parle volontairement de rôle, c'est en fonction de la taille des équipes. On va avoir des personnes qui vont être peut-être dédiées sur un rôle particulier comme on peut avoir des gens qui vont cumuler les rôles si c'est une petite équipe pour une petite application, on voit que l'adaptateur en fait il est codé par les deux. C'est le développeur qui va faire l'API, qui va donner les pistes pour le SDK cloud. C'est le développeur métier qui va consommer en fait ce SDK cloud. Et surtout, on se rend compte qu'on en arrive à avoir un besoin de ressources où on va cumuler un petit peu les deux rôles : développeur métier et développeur infrastructure. Et on retombe en fait sur ce que disait Sébastien un petit peu plus tôt : on en est à rechercher des moutons à cinq pattes, c'est-à-dire des gens qui ont une expertise sur un langage, qui ont une expertise sur un métier, mais qui ont en même temps les compétences au niveau de l'infrastructure, de la sécurité pour faire les choses proprement.
Et c'est là où on arrive à une équipe élargie où on va avoir des rôles qui ne vont pas suivre le même cycle de déploiement. Moi, je sais que pour être intervenu en mission en tant que développeur infrastructure sur un déploiement applicatif dans le formalisme agile, je me trouvais - vous avez peut-être vécu des choses similaires de votre côté - je me retrouvais sur des cérémonies, embarqué dans des cérémonies où on me demandait de me positionner sur des choix métiers pour lesquels je n'étais pas pertinent parce que ce n'était pas mon objectif de mission. Donc voilà, ça faisait une situation que je trouve qui n'est pas très confortable au niveau de l'agilité.
Et donc dans ce cadre-là, le fait de mieux répartir les compétences devient une obligation. Alors beaucoup de sociétés mettent en place des Cloud Center of Excellence. Ça peut être aussi en charge de la DSI, ça peut être aussi la première équipe qui va déployer dans un cloud, qui va mettre à disposition des autres équipes, des autres projets, l'adaptateur qui va bien mais qui respecte les bonnes pratiques.
Après, si on regarde là, on raisonnait sur une application. Si on regarde sur un ensemble d'applications au sein d'une entreprise, beaucoup de sociétés font des "move to cloud" avec des centaines d'applications à bouger. Si on garde toujours cette approche, admettons j'ai trois applications qui vont consommer un bucket S3, donc je vais avoir trois SDK cloud qui vont être développés chacun dans leur coin. Et avec pour conséquence, en fait, le même travail est fait plusieurs fois. C'est le fait de coder ces interactions S3. On a une implémentation hétérogène.
C'est alors un cas d'école qui ne se fait plus maintenant, mais ça sera une base de données typiquement. Sur mes centaines d'applications, je vais peut-être en retrouver une avec mon login et mot de passe en clair dans le code. On va avoir des montées de version longues. Par exemple, je suis sur AWS, mon SDK cloud je l'ai codé en Boto 3. Donc j'ai mes centaines d'applications qui utilisent Boto 3 par exemple pour interagir avec AWS. AWS sort Boto 4 avec correction de failles de sécurité, nouvelles fonctionnalités et tout ça. Eh bien, ça veut dire que mes centaines d'applications vont devoir repasser, vont devoir recoder, vont devoir retester, vont peut-être devoir intégrer de nouvelles choses parce qu'il y a des choses dépréciées entre le 4 et le 3.
Et là où c'est problématique, c'est que c'est ce fameux code en fait qui va garantir toutes les bonnes pratiques en termes de sécurité et d'observabilité. Alors il faut aussi savoir que cette multiplication des implémentations, cette complexité dans l'implémentation et dans la multiplicité fait que ça devient du cloud legacy, du code historique qui est difficile à maintenir, à faire évoluer et qui du coup reste et devient le boulet de l'entreprise, qui a sauté une mise à jour par faute de temps.
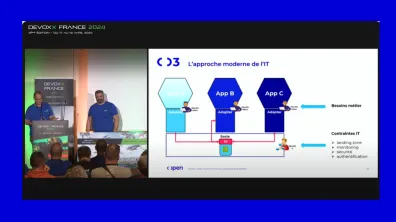
Du coup, cela devient encore plus compliqué à mettre à jour et ralentit probablement la totalité des équipes. Donc en fait, nos réflexions nous ont amenés à penser une approche un petit peu plus moderne de l'IT que ce qu'on a constaté actuellement. C'est en fait, plutôt que chaque équipe fasse sa couche basse, on va avoir un socle commun. Dans ce socle commun, on va retrouver, je prends l'exemple avec Terraform, on va faire un module Terraform qui va implémenter par service, qui va implémenter vraiment proprement mon service cloud ou on-premise. Pour nous, un data center est un cloud comme un autre, qui va l'implémenter proprement avec tous les éléments de sécurité, qui va être conforme à la politique de l'entreprise.
À ça, on va avoir associé une portion de code qui va être dédiée vraiment aux interactions avec le service et qui est très intimement liée en fait à ce qu'on a fait en Terraform. Et en fait, c'est ce code-là qui va être consommé par les adaptateurs. L'intérêt de cette approche, c'est qu'on peut très bien dire que ce code-là, ce socle-là peut être développé par les rôles développeur IT, avec l'intérêt que c'est une équipe qui va être en contact direct avec les contraintes IT de l'entreprise. Parce que les DSI, en fait les services IT, mettent en place des solutions qui sont globales, qui vont couvrir toutes les applications de la boîte et qui vont imposer des normes de fait au niveau du fonctionnement, ne serait-ce que pour la sécurité, le protocole d'authentification, tout ce qui va être monitoring, tout ce qui va être la landing zone, les intégrations landing zone. Et donc ce sont des contraintes qui peuvent être embarquées par ces rôles de dev qui vont les implémenter dans les modules, permettant ainsi aux applications qui s'appuient dessus d'atterrir proprement dans l'écosystème cloud de l'entreprise.
Alors l'intérêt de ça, c'est que du coup, les équipes de dev métier se centrent vraiment sur ce qui est l'objectif absolu de l'agilité, c'est la business value. J'ajoute aussi que sur un aspect, ce qu'on voit de plus en plus maintenant dans les grandes sociétés, c'est que dès qu'une application doit être posée dans le cloud, il y a toute une étape de validation au niveau de la cybersécurité. Ça peut être un accélérateur de cette validation puisque si une application est bâtie sur un ensemble de briques qu'on va retrouver dans notre socle, qui ont déjà été validées par la cybersécurité, de fait cette validation est accélérée.
Donc cette approche de pouvoir faire en sorte de développer en transverse des assets, effectivement ça va donner de la rapidité, de la flexibilité au projet. Il n'y aura pas besoin que le projet devienne un expert sur un cloud en particulier pour pouvoir déployer sur ce cloud. Ça va être un travail qui va être partagé entre l'expert du cloud, qui mettra à disposition un asset particulier, et le code métier. L'équipe projet se concentrera sur le code métier qui pourra être déployé partout.
Du coup, pour le moment, on n'a pas vraiment parlé de multicloud, mais en fait dans notre réflexion, on s'est rendu compte que prendre une approche multicloud, quelque part ça revient à prendre, modulariser le code et retrouver les best practices de l'informatique. Le fait de factoriser tout dans des modules spécifiques, c'est ce que font les développeurs usuellement. Et en fait, on se rend compte que les services cloud fonctionnellement, ils sont similaires. On va prendre S3, Storage Container, on va prendre AWS Lambda, Azure Function, RDS ou Azure Database. On se rend compte qu'il est tout à fait possible de définir des paramètres d'infrastructure as code qui vont être communs, que ce soit l'un ou l'autre.
Si je suis sur le S3 object storage, ça va être le nom qu'on va lui donner, le nom court du high-level design ou le nom complet quand on déploie le service, ça va être des ACL et ça va être par exemple les notifications que ce service est en capacité d'émettre. Au niveau d'une fonction, elle a un nom et elle a un runtime. Au niveau d'une base de données, elle a un nom, elle a un engine. À côté de ça, on va avoir des interfaces qui vont être communes côté code. Par exemple, que ce soit S3 ou object storage, on n'a pas 150 000 fonctions qu'on utilise. On va lire, on va écrire, on va renommer, on va supprimer, on va lister les objets. Une fonction, on l'invoque. Une base de données, on récupère la connexion pour passer nos SQL derrière.
Et enfin, on peut trouver et faire un travail de réflexion pour trouver des classes communes, un nommage commun pour toutes ces classes, pour les remettre un petit peu dans le même cadre. On va dire que par exemple un S3 et Storage Container, c'est un object storage. Une fonction ou basiquement une database. Alors cette approche-là, elle n'est pas... enfin, on n'est pas les premiers à la faire. On peut citer Dapr, qui a déjà cette approche de pouvoir modulariser les différents types d'objets et de pouvoir aussi bien attaquer de l'EventHub, du Kafka que des services bus, et en changeant la configuration, faire en sorte que notre application soit totalement agnostique.
Le but de se dire que déjà de se mettre dans cette approche-là, c'est de peut-être choisir Dapr ou d'implémenter quelque chose qui correspond véritablement à votre contexte si vous avez des besoins soit techniques, soit pour implémenter les concepts de sécurité ou de ségrégation réseau dont vous avez besoin spécifiquement pour votre société. Vous pouvez aussi implémenter pour vos besoins des types d'objets et donc les adaptateurs qui correspondent pour un cloud en particulier.
À côté de ça, donc on va pouvoir, partant de ce constat, on va pouvoir au niveau du code par exemple faire un ensemble d'objets. C'est-à-dire que l'idée, là je pars de S3, au niveau de mon code quand je vais coder mon SDK, je vais avoir une classe, on va dire abstraite ou une interface, tout dépend, c'est un choix d'implémentation. Je vais définir une interface que je vais appeler "object" qui va implémenter toutes ces fonctions et je vais pouvoir la décliner en fait par service, par hyperscaler ou on-premise.
Elles vont être, et cette interface-là, elle va être unique pour tous les clouds. Elle va être étroitement liée au module Terraform correspondant et elle va implémenter les méthodes en utilisant le SDK du cloud provider. À cette classe-là, on va rajouter ce qu'on appelle une couche d'abstraction qui va être initialisée d'après l'ensemble des services. C'est-à-dire que je vais implémenter ma fonction Lambda, dans ma fonction Lambda je vais lui passer au format JSON en variable d'environnement la liste par exemple des services AWS auxquels elle doit accéder, telle base RDS, tel S3, et cette couche va s'initialiser et va créer des instances de type object storage qu'on a en bas et elle va proposer par exemple, un accès simplifié en mode dictionnaire avec le logical name. Le logical name, ça va être ce que je vais avoir dans mon high level design, c'est par exemple mon bucket CRM dans le high level design versus le nom déployé : nom d'environnement, un ID, CRM et tout ça.
Alors bien sûr, cette approche en fait est à adapter dans votre contexte selon les cloud providers. Le but n'est pas d'implémenter immédiatement pour tous les cloud providers l'adaptateur pour le S3, pour l'event hub ou pour la base de données, mais de le faire au fur et à mesure selon vos compétences disponibles, selon les besoins, et de vous permettre en fait de gagner en agilité assez rapidement.
À côté de ça, je vais avoir un travail similaire au niveau de mon Terraform. C'est-à-dire que je vais fonctionner par module, je vais implémenter mes modules par provider, par service, et je vais appliquer un pattern. Par exemple, dans mes inputs de modules, je vais définir tout ce qui va être les ACL. Dans mes outputs de modules, je vais définir tous les composants d'identité type, les rôles, plus des références à mon service. Et je vais créer ce qu'on appelle un module de relation où, par exemple, je vais créer ma Lambda, je vais créer mon bucket S3, et entre les deux, je vais créer mon module Terraform. Je vais appeler mon module Terraform en passant l'identité de ma Lambda, l'identité de mon S3, le niveau d'accès que je veux, et c'est en fait ce module Terraform qui va faire l'attachement au rôle.
Cette approche-là, en fait, avec des modules qui sont codés en étant extrêmement attentifs à tout ce qui va être least privilege, sécurité, tout ça, ce sont ces modules-là qui vont permettre de garantir que chaque service sera correctement déployé en respectant tous les aspects de sécurité. C'est en étant particulièrement aussi attentif aux politiques de tag, c'est là où je vais pouvoir mettre en œuvre tout ce qui va être FinOps, Green IT, parce que c'est systématisé. Ça va être systématisé au niveau de mes services, ça va être systématisé au niveau de ma sécurité, ça va être systématisé au niveau de mon réseau.
Donc en fait, le fait d'avoir des interfaces uniques et simplifiées, dans notre esprit, c'est cette vision-là qui est très orientée vision développeur métier. On va vraiment raisonner au niveau high level design, donc avec un ensemble de modules. Et avec la souplesse que Terraform... on l'a implémenté en Terraform, mais ça serait tout à fait faisable en CDK ou autrement. Dans le modèle, dans la démo que nous avons codée, en fait ce qui va déterminer mon infrastructure, c'est un fichier YAML où je vais décrire les services que je veux et les relations que je veux leur donner.
Donc à titre d'exemple, je vais déclarer... Je suis désolé, je parle beaucoup d'AWS, c'est... Donc j'ai le... je vais avoir mon object storage qui va être un bucket S3. Le développeur, par exemple dans la section du fichier, va dire "object storage", va dire "j'ai un object storage, son logical name c'est CRM". Par contre, Terraform va le déployer avec le nom complet en respectant les conventions de nommage de l'entreprise. Il va dire "j'ai une fonction, je veux qu'elle s'appelle CRM import et son répertoire sources est à tel endroit". Ça va le créer avec le nom complet, et cette fonction-là, dans le modèle qu'on a déployé, va inclure une layer avec la couche d'abstraction en Python.
Va inclure le Lambda qui est unique pour toutes les fonctions, qui implémente la couche d'abstraction, qui initialise tous les objets en fait qui représentent les services. On va créer une relation. La relation, là j'indique que je veux que ma CRM import fonction accède à un object store. On peut même donner des niveaux assez fins en termes de paramétrage.
Et enfin, finalement, le code du développeur métier vient par-dessus cette stack et est invoqué par mon Lambda handler standard qui va lui passer tous les objets de configuration, toute la couche d'abstraction layer. Et à ce moment-là, le métier intervient. Alors dans ce cadre-là, en fait, l'équipe métier déploie, enfin crée véritablement uniquement son code fonctionnel. Il va définir les relations entre les différents objets, les droits nécessaires, et si vous avez des équipes sécurité ou des équipes réseau qui vous demandent des schémas de flux ou les dépendances que vous avez sur telle ou telle application, en fait ça permettrait, cette approche, de fournir extrêmement rapidement, vu que c'est dans la configuration pour le déploiement, ça permettrait de bien définir qu'on n'a pas besoin de plus parce que sans ça, on ne déploie pas.
Donc, et du coup pour aller un petit peu plus dans le code, le code métier, c'est... Alors dans ce que, dans l'exemple qu'on a fait, nous, on appelle une fonction qui s'appelle "process" et c'est dans cette fonction-là que le développeur métier va attaquer son code. Cette fonction "process" en fait, elle est définie, reçoit un event. L'event, alors je ne sais pas si vous voyez vraiment bien l'event, en fait, l'event va être... j'ai le terme anglais, j'arrive plus... va être traduit. L'event va être traduit depuis l'event JSON reçu par exemple depuis le cloud provider.
Si on a bossé avec S3, les notifications de S3 arrivent avec un JSON qui va être énorme où on va avoir le nom complet du bucket. Voilà, là l'idée c'est que la couche d'abstraction en fait fait une traduction de l'event pour se ramener à nouveau sur les nommages high level design. Par exemple, là on voit clairement ma source c'est un object storage, mon event c'est un object created, le nom de mon object storage c'est "incoming" et mon objet c'est "customer.csv", alors qu'en réalité le nom complet du bucket c'est le nom qu'on a l'habitude de voir dans AWS.
À côté de ça, quand je vais vouloir invoquer mes services, du coup je suis en capacité, en utilisant cette bibliothèque-là, je suis en capacité de rappeler en fait mes classes que j'ai utilisées pour faire mes interactions, toujours au travers du nom logique. Et ce qui fait que j'ai un code, c'est ce que vous pouvez voir à l'écran, qui en termes de bibliothèque est complètement agnostique du cloud provider. Et l'intérêt, c'est que ce code-là, je suis en... c'est dans la démo que nous avons faite, ça fonctionne en local. Ce code-là, il va tourner... Je reprends le même code, je déploie dans AWS, mais avec les couches sous-jacentes pour AWS, mon code va tourner à l'identique sans modification. Et donc il pourrait tourner sur Azure, sur OVH, Scaleway, tous les cloud providers.
En conclusion, déjà merci. La démarche, donc ça va reprendre trois principes :
- Gérer la qualité de code, faire en sorte que les équipes puissent utiliser les assets mais tout en respectant les bonnes pratiques en termes de sécurité, de clean code, de testabilité, de mettre en place aussi des tests automatisés, donner la possibilité de mettre les tests automatisés.
- En termes de robustesse, c'est résister au breaking change, permettre, en ayant un adaptateur qui n'est plus dans chacune des applications mais qui sera transverse, de plus facilement pouvoir mettre à jour pour ne pas subir le breaking change.
- Et en termes de maintenabilité, toujours encore une fois mettre à jour le plus vite possible, le plus simplement possible sans impacter les équipes projets.
Alors on parle de tous ces avantages-là : masquer la complexité, laisser les équipes se concentrer sur le code métier, pouvoir faire en sorte qu'on puisse aller très vite. Donc beaucoup d'avantages.
Merci beaucoup de votre attention. Alors en fait, on dépasse un petit peu le temps, on aurait beaucoup, beaucoup de choses à dire en plus. Donc venez nous voir sur le stand, on a aussi une démo de toute cette implémentation qui fonctionne et qu'on va vous présenter sur le stand. Donc venez nous voir.
Merci. Alors si vous avez des questions, c'est maintenant. On sera ravi d'y répondre.
[Question du public] Bonjour. Merci. Si je comprends bien, à chaque fois les couches d'adaptation, elles sont embarquées avec le code qui a besoin de tourner. Est-ce qu'il n'y a pas une possibilité d'aller un peu plus loin et puis de déployer ça de manière unique avec des liens RPC entre l'adaptateur et un service qui serait déployé ? Tout ça peut être soit sur du déploiement dans Kubernetes avec des sidecars, donc qui seraient en fait dédiés à ces couches d'adaptation. Ça peut être en mettant en place des NuGet packages qui seraient récupérés lors de la compilation, qui ferait qu'on télécharge toujours la dernière version disponible.
[Réponse] Ça, on peut avoir beaucoup d'implémentations différentes de cette mise à disposition des adaptateurs. Moi, je pense surtout au côté multi-techno. C'est que là, on a vu l'exemple en Python, mais si on a du Go, du Python, du Java, effectivement, on pourrait avoir en .NET, en Java, donc des adaptateurs qui sont liés. On pourrait aussi avoir des passe-plats qui feraient qu'en .NET, on appellerait une technologie qui ferait ce rôle d'adaptation. Et du coup, en fait, on a juste des passe-plats qui font qu'on peut facilement appeler le même adaptateur selon la technologie. C'est tout l'utilisation de Dapr, par exemple.
[Question du public] Oui, on parle de multicloud, mais il y a un des trucs que vous avez omis, c'est le transfert des données entre les applications. Et en fait, si on est multicloud, on ne va plus tellement voir, enfin avec votre système, on ne va plus tellement voir le fait qu'on transfère d'un cloud à un autre. Or, ça a un coût assez énorme de transfert multicloud. Donc cacher l'hétérogénéité des clouds, ce n'est pas forcément une bonne idée.
[Réponse] On ne cache pas l'hétérogénéité, tu facilites le transfert entre les deux. Certes. Mais de toute façon, quel que soit le cloud, quand tu prends un développeur débutant, tu lui fais un appel de méthode locale ou un appel de méthode distante, lui, il ne voit pas la différence, il est débutant. Absolument. Donc il faut connaître le coût de ce qu'il y a derrière.
Effectivement, c'est bien ma vigilance par rapport à ça. Dans le cadre d'une mise à jour sur un cloud provider quel qu'il soit, effectivement, il y a le coût de passage de l'un à l'autre. Mais si tu te rappelles le passage où on définit les dépendances entre chaque couche, en fait, le fait de connaître ces flux-là permettrait à un architecte, au moment de la validation, de pouvoir se dire : "Bah, les données sont au Japon et on les fait transiter par la Chine et ensuite on les envoie au Danemark". Et en fait, le fait de pouvoir avoir cette approche et de définir les relations entre les applications, ça permet de lutter contre ça.
On... de toute façon, si on fait du multicloud, quelle que soit la technologie, ce que tu décris ici, d'avoir les données qui sont passées de l'une à l'autre, on l'aura. Donc il faut se donner les moyens de, au moins, le citer, d'au moins le décrire.
Je dirais, c'est décrit par défaut parce que là, on est resté... nous, ce qu'on voulait mettre vraiment en avant, c'est cette démarche de faire une abstraction. Maintenant, ce qu'il faut... on est resté sur un mono-cloud, on est en on-premise, on est dans AWS. Maintenant, le fichier YAML que je présentais tout à l'heure, qui présentait tous les services qu'on déploie, si je suis en mode multicloud, je peux très bien imaginer avoir un fichier YAML avec une portion AWS, une portion Azure, une portion GCP. Et ça va être le choix de l'architecte aussi d'établir ça, de mettre en place les liens. Les liens vont être visibles dans le fichier.
C'est ce que je veux dire, c'est que le développeur dans ce contexte-là n'a pas à se poser cette question-là. C'est... il y a eu un architecte, il y a eu un tech lead qui a décidé qu'on faisait cette ventilation de ressources, mais elle est documentée par défaut. Le fait d'avoir ce besoin de gouvernance, de tout, quel que soit l'outil qu'on utilise, on en a besoin. Par contre, on permet, nous, d'avoir un fichier qui le décrit.
D'autres questions ? Pas d'autres questions ? Merci beaucoup.
Pourquoi le multicloud ?
-
S’adapter aux besoins spécifiques des projets
-
Réduire la dépendance à un cloud Provider ou à une implémentation locale
-
Respecter les conditions contractuelles ou réglementaires
-
S’implémenter dans une région géographique pour une ressource spécifique ou se rapprocher du besoin
-
Facilité la cohabitation de SI hétérogènes
Kubernetes vs Cloud natif : quels sont les avantages et inconvénients ?
Kubernetes offre une personnalisation et une scalabilité exceptionnelles, permettant aux équipes de déployer et de gérer des applications de manière flexible et efficace.
Mais cette personnalisation, la maintenance et la résilience nécessitent des administrateurs dédiés avec des compétences spécifiques.
Les solutions cloud natives se distinguent par leur simplicité, les besoins de gestion et maintenance, et les niveaux de services garantis par le provider.
Chaque implémentation présente des défis, des avantages indéniables et des inconvénients distincts.
Ainsi, le choix entre Kubernetes et le cloud natif dépendra des besoins spécifiques de chaque projet à un moment donné.
Notre conviction est de faciliter ce choix
Les défis de la complexité.
Implémenter des applications sur de multiples instances Cloud ou On Premise représente de nombreux challenges :
- La complexité croissante dans la mise en œuvre et la gestion de chaque implémentation
- Des mises à jour manquées entraine de la dette technique et des applications Legacy
- Maitriser tous les environnements techniques en plus de maitriser le fonctionnel rend le recrutement délicat
- Chaque projet ayant des contraintes et besoins particuliers, une seule implémentation de plateforme ne conviendra pas pour tous.
Maximisez l'efficacité de vos déploiements multicloud.
La démarche proposée par Open permettra à chaque projet de choisir son implémentation en fonction de ces besoins spécifiques à un instant t. Tout en autorisant cette même application à déployer sur un autre cloud ou une autre implémentation sans tout réécrire ou retester.
Ceci comprend la nécessité de rendre les applications agnostiques vis-à-vis du fournisseur de cloud pour garantir la portabilité. Mais également de travailler à la modularisation des déploiements Iac pour chaque cloud providers.
En créant un socle technique commun, incluant les adapteurs et les modules Iac, commun à toutes les équipes de l’entreprise.
Cette rationalisation simplifie le développement et la maintenance des socles techniques en évitant les redondances.
La gouvernance, la sécurité et la gouvernance sont également simplifiées car portées par une équipe dédiée DSI. Les bests practices pourront imposer plus rapidement et plus efficacement les bests practices et les mises à jour de sécurité.
Les équipes projets se concentrent sur le code métier.
En somme, notre ambition via cette approche, c'est de
- Donner le choix aux projets (Kube, PaaS ou les 2)
- Permettre le déploiement d'un même code métier sur n'importe quel cloud
- Faciliter l'adaptation des applications Legacy pour un Move to Cloud
- Favoriser une meilleure répartition des compétences / responsabilités
- Garantir une meilleure gouvernance.




